محققان موفق پیشبینی ساختار ۶۰۰میلیون پروتئین با هوشمصنوعی در ۲ هفته شدند
رمزگشایی هوشمصنوعی از ساختار پروتئینهایناشناخته
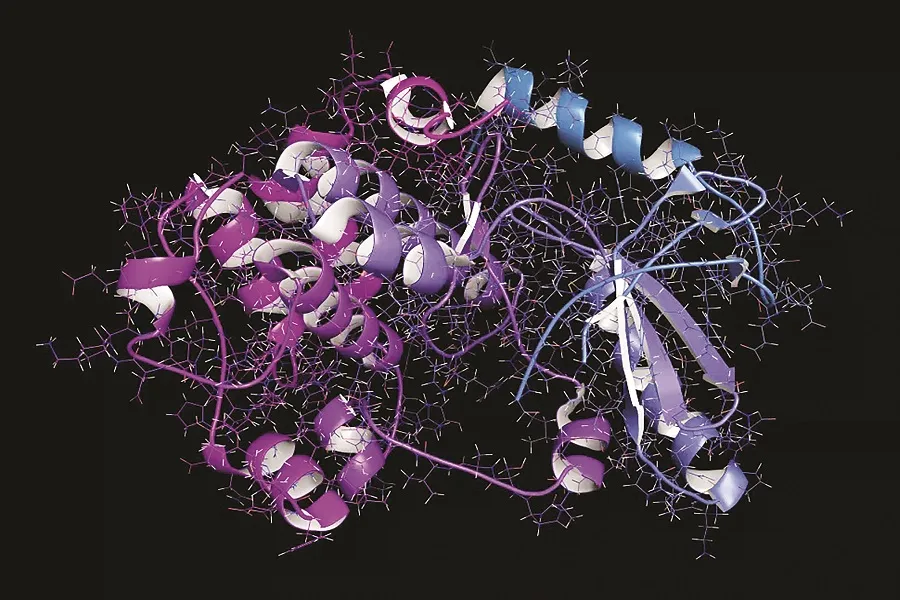
پروتئینها واحدهای سازنده همه موجودات زنده هستند و از زنجیرههای بلند و پیچدرپیچ اسیدهای آمینه تشکیل شدهاند. درک ساختار و عملکرد پروتئین برای فهم ما از فرآیندهای زیستی ضروری است.
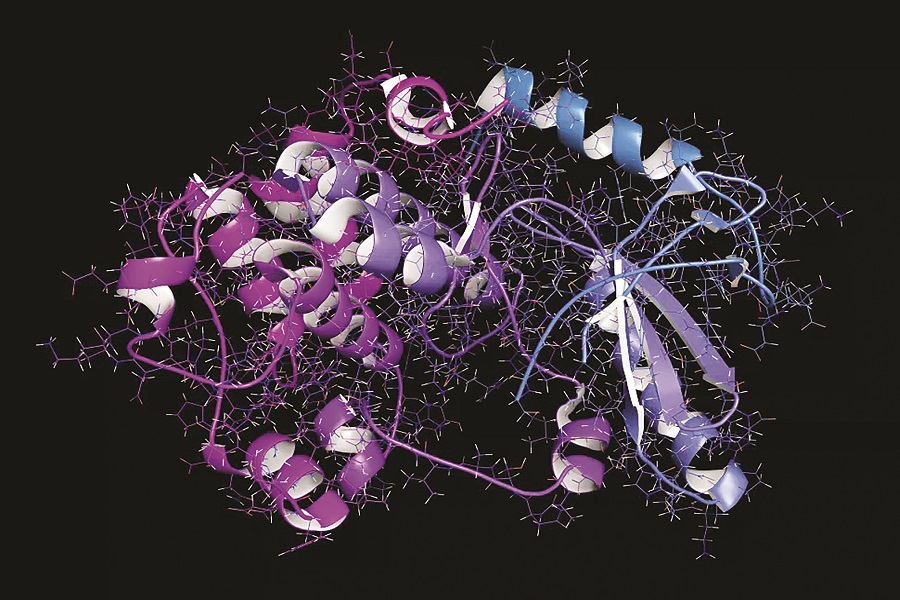
با روشهای مرسوم شکل درصد اندکی از پروتیئنها پیشبینی شده، اما بهتازگی دانشمندان شرکت متا، شرکت مادر فیسبوک و اینستاگرام، از یک مدل هوشمصنوعی برای پیشبینی ساختار بیش از ۶۰۰میلیون پروتئین متعلق به ویروسها، باکتریها و سایر میکروبها استفاده کردهاند.
استفاده از مدلهای یادگیری زبان
این برنامه که ایاسامفولد (ESMFold) نام دارد، از مدلی استفاده کرده که در ابتدا برای رمزگشایی زبان انسان طراحی شده بود. مدلهای یادگیری زبان شکلی از هوشمصنوعی هستند که یادمیگیرند الگوهای زبان را پیشبینی کنند، جای خالی حروف در کلمات را حدس بزنند و حتی کلمات و جملات بعد را پیشبینی کنند. هوشمصنوعی حتی میتواند تا آنجا پیش رود که معنای کلمات را درک کند. استفاده از این مدل برای پیشبینی ساختار پروتئینها ایده جدیدی است. این ایده بر این منطق استوار است که الگویی اساسی در رابطه با چگونگی تکامل پروتئینهای مرتبط با هم وجود دارد.
با ارائه توالی اسیدهای آمینه به این مدل یادگیری زبان به نحوی که انگار این توالی اسیدآمینهها مانند کلمات هستند، مدل باید بتواند در مورد سایر توالیها پیشبینی کند و درنهایت بتواند پیچشها و چرخشهای پروتئینهایی را که ساختار سهبعدی آنها را تعیین میکند، پیشبینی نماید. این پیشبینیها از ساختار پروتئینها، که در «اطلس متاژنومیک منبع باز» گردآوری شده است، میتواند برای کمک به توسعه داروهای جدید، مشخص کردن فرآیندهای میکروبی ناشناخته و ردیابی ارتباطات تکاملی بین گونههای دوردست مورد استفاده قرار گیرد.
سبقت متا از گوگل
ایاسامفولد اولین برنامهای نیست که به پیشبینی ساختار پروتئینها میپردازد. امسال، شرکت دیپمایند متعلق به گوگل اعلام کرد که شکل تقریبا ۲۰۰میلیون پروتئین شناختهشده را رمزگشایی کرده است. به گفته متا، ایاسامفولد به اندازه نتایج دیپمایند (DeepMind) گوگل دقیق نیست، اما ۶۰برابرسریعتر است. دانشمندان برای اینکه صحت مدل خود را آزمایش کنند، از پایگاه دادهای از دیانای متاژنومی استفاده کردند؛ یعنی مواد ژنتیکی که مستقیما از مکانهایی مانند خاک، آب دریا و روده و پوست انسان گرفته شدهاند. آنها با این اطلاعات توانستند ساختار بیش از ۶۱۷میلیون پروتئین را طی دو هفته پیشبینی کنند. این عدد ۴۰۰میلیون بیشتر از آن چیزی است که شرکت دیپمایند متعلق به گوگل چهار ماه پیش اعلام کرده بود. دیپمایند ادعا کرده بود که ساختار تقریبا هر پروتئین شناختهشدهای را برآورد کرده است. این به این معناست که بسیاری از این پروتئینها قبلا دیده نشدهاند، احتمالا به این دلیل که از موجودات ناشناخته میآیند.
گفته میشود بیش از ۲۰۰میلیون پیشبینی پروتئین برنامه ایاسامفولد با کیفیت بالا محسوب میشوند، به این معنی که این برنامه قادر است شکل آنها را با دقتی تا سطح اتم پیشبینی کند. روش استاندارد برای تعیین ساختار پروتئین، استفاده از کریستالوگرافی اشعه ایکس است - مشاهده چگونگی پراکندگی پرتوهای پرانرژی نور در اطراف پروتئینها -، اما این روش پرزحمت و زمانبر است و برای همه انواع پروتئین نمیتوان از آن استفاده کرد. پس از چند دهه کار، فقط حدود ۱۰هزار ساختار پروتئینی از طریق کریستالوگرافی اشعه ایکس رمزگشایی شده است.
محققان امیدوارند از این برنامه برای کارهای متمرکز بر پروتئین استفاده کنند. شرکت متا گفته است: «برای توسعه بیشتر کار، ما در حال مطالعه این موضوع هستیم که چگونه مدلهای زبانی میتوانند برای طراحی پروتئینهای جدید و کمک به حل چالشهای سلامت، بیماری و محیط زیست استفاده شوند.»
روزنامه جام جم

تازه ها















گفت و گو

در گفتوگو با دکتر عنادی مطرح شد:
باید روایت ایرانی الموت و حسن صباح را خودمان بسازیم



در گفتوگو با جامجم آنلاین عنوان شد